Machine Learning-Powered Encrypted Network Traffic Analysis: A Comprehensive Survey -- 2023

流量分析是监控网络活动、发现特定模式并从流量中收集有价值信息的过程。它可以应用于网络断言探测和异常检测等各个领域。然而,随着流量加密的出现,流量分析成为一项艰巨的任务。由于数据包有效载荷的不可见性,依赖于从明文有效载荷中捕获有价值信息的传统流量分析方法很可能会失去效力。机器学习已经成为一种强大的工具,可以在不访问有效载荷的情况下提取信息特征,因此在加密流量分析中得到广泛应用。在本文中,我们对机器学习驱动的加密流量分析的最新成果进行了全面调查。 首先,我们回顾了这方面的文献,并总结了作为文献分类基础的分析目标。然后,我们抽象了使用机器学习工具进行加密流量分析的工作流程,包括流量收集、流量表示、流量分析方法和性能评估。对于被调查的研究,不同的分析目标对分类颗粒度和信息时效性的要求可能会有很大差异。因此,在流量分析的目标方面,我们根据网络资产识别、网络表征、隐私泄漏检测和异常检测四大类对现有研究进行了全面回顾。最后,我们讨论了加密流量分析未来研究的挑战和方向。
引言
- 加密流量是保护隐私的重要方式,谷歌提供的95%以上的服务头应用了加密协议。但是加密的流量负载信息使得传统的流量分析方法失去效力,许多攻击者会利用加密协议隐藏恶意内容来逃避异常检测,这使得通过流量分析检测网络异常变得困难。
- 现在的机器学习技术无需访问数据包有效载荷,它利用加密流量的统计特征和行为特征进行分析。此外,深度学习方法还能够避免人工特征提取的过程,这使得它成为处理不断变化的流量模式的理想方法。
- 文章的贡献主要有:概述了流量分析的总体过程,包括流量采集、流量表示、流量分析方法设计和性能评价。根据分析目标对现有方法进行了系统分类,包括网络资产识别、网络表征、隐私泄漏检测和异常检测。探讨加密流量分析的未来方向
加密流量分析概述
-
系统模型

-
加密流量分析的分类:文中根据流量分析的目标进行分类,提出了对应于不同应用领域的四个宏观目标,包括网络资产识别、网络表征、隐私泄漏检测和异常检测。
- 网络资产识别:目的是识别物理网络设备和操作系统,以便于管理庞杂的网络设备。即便流量进行了加密,也可以通过一些流量特征进行网络资产识别。
- 网络表征:目的是为了了解服务的质量和相关协议。
- 隐私泄露检测:目的在于分析加密流量可能泄露的信息。虽然加密流量一定程度上保护了隐私,但是由于不同网站的流量存在差异,且用户在应用中产生的流量存在行为特征,这都成为隐私泄露的可能。文中提到三种隐私泄露识别,即网站指纹(WF),应用指纹(AF)和用户操作识别。
- 异常检测:目的在于检测各种恶意软件和网络异常。传统的检测方法对于加密载荷已经失效,但是异常行为流量与正常行为流量仍有差异,使用机器学习的方法仍然有效
机器学习背景
- 分类:监督、无监督、半监督、强化学习
- 深度学习相比于机器学习具有更高的复杂度,大多数深度学习方法利用神经网络层的级联,其中包含用于特征提取的非线性处理单元,但是机器学习通常需要更多的特征工程。
- 流量分析中,特征提取是至关重要的一部分,之前许多研究集中于如何自从字节流中提取有效的语义信息。但随着深度学习的出现,特征工程与传统机器学习相结合,原始信息与深度学习相结合是流量分析成为两种常见方法,前者更侧重于有效特征的提取,而后者更侧重于构建具有较强特征提取能力的模型。
- 传统机器学习
- 贝叶斯方法:基于贝叶斯定理和条件无关俄分类方法。它假设特征是相互独立的。
- 马尔科夫模型:它是一个随机模型,给出了随机状态变化的概率。一个马尔科夫过程就是指过程中的每个状态的转移只依赖于之前的 n个状态,这个过程被称为 n阶马尔科夫模型,其中 n是影响转移状态的数目
- k近邻(k-NN):是一种常见的监督学习方法。对于给定目标样本,它找出最近的k个样本,根据这些领域预测信息。基本思想是一个样本的k个最邻近的样本大多属于某一个类别,则这个样本也划分为这个类别。
- 支持向量机(SVM):通常用于二分类任务。其核心思想是找到一个超平面,将不同类别的样本分开,并且使得分类间隔最大化。
- 决策树(DT):由有向边和节点组成,有向边和节点包括根节点、内部节点和叶节点。从根节点到每个叶节点的路径对应于一个决策序列。容易被噪音影响,容易过拟合,难以并行,性能差。
- 随机森林(RF):即多个决策树的集合,针对DT容易过拟合的缺点,RF采用基于多个DT的投票机制进行改进。每棵树都独立训练。
- 传统的机器学习技术本质上是浅学习,在分类任务的准确性方面有一定的局限性,一般泛化能力都较弱。常见的深度学习方法有CNN、GNN、LSTM
加密流量分析的通用框架
-
主要包括流量采集、流量表示、流量分析方法和性能评估
-
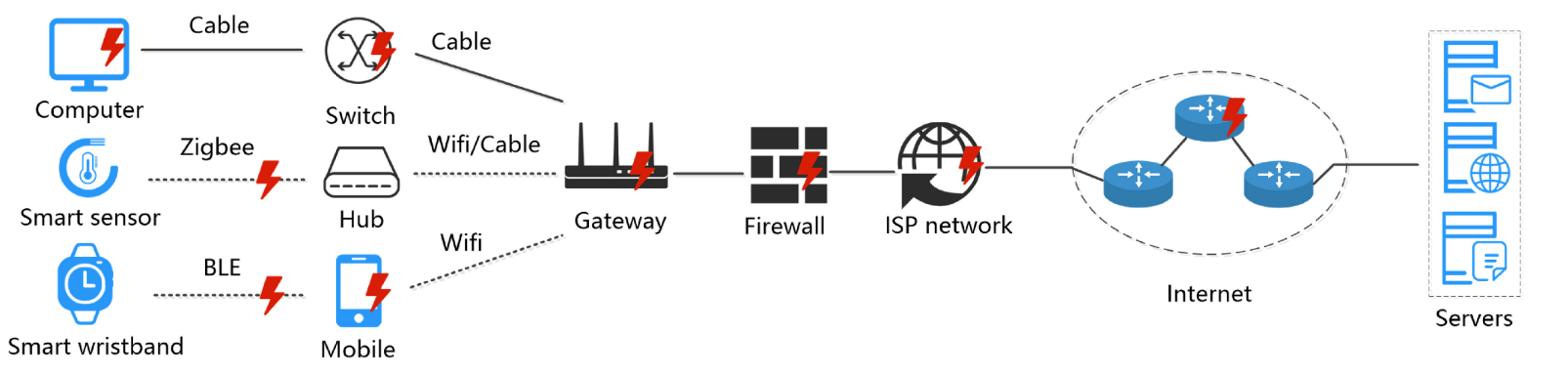
常见的加密协议有网络层的IPSec、传输层和应用层的SSL/TLS和QUIC以及应用层的SSH、HTTPS、Tor等
-
流量采集:可以在网络中各个节点进行捕获。常用的捕获工具有Libpcap、TCPdump、wireshark、Netflow
-
流量表示级别:流级和会话级
- 流级:流是指在一定时间间隔内具有特定公共属性的数据包集合,公共属性通常指五元组。流级表示中可以提取的统计特征如平均数据包计数、最大数据包长度或最小间隔时间。
- 会话级:会话是客户端和服务器之间完整交互过程产生的数据包的集合。一个会话的报文可能具有不同的属性,所以一个会话可能包含多个流。流的大小没有限制,例如,一个流可能只包含一个数据包。但是,一个会话必须包含一个完全交互的过程,因此它至少包含两个与建立交互过程相关的数据包。同时,从流级表示中提取的统计特征也适用于会话级表示,因为会话的本质仍然是数据包的集合。此外,流的计数或流的平均持续时间等其他特征也可以提取为会话级特征。
-
流量表示形式
- 基于包的特征:通常数据包的五元组是最常用的特征,此外,还有IP报头的生存时间、TCP报头的初始窗口大小也可以作为特征提取出来,这些是直接从数据包中获得的最简单的特征
- 统计特征:通过抽象或计算从一组数据包中提取的特征。通常包括期望值、偏差、平均值、最小值、最大值、中位数、累积等。将这些统计信息与报文大小、到达间隔时间、报文数等流量属性结合,可以得到大量的统计特征,如累计报文大小的平均值、到达间隔时间的四分位数、突发报文数等
- 原始流量表示:人工特征提取是基于经验的,而原始表示将特征选择的任务转移给了模型。有些研究在数据预处理部分将流量编码为序列、图、图像进行分类。
-
加密流量分析方法:机器学习方法需要依赖复杂的特征工程,这需要大量的先验知识,而且泛化能力差,面对复杂问题时性能受限。而深度学习可以将原始流量表示作为输入,可以解决这些限制。
-
性能评估方法:训练集和测试集分别用来训练模型和验证模型。可以使用不同的划分方法来划分出两个数据集,k-fold交叉验证是最常用的方法,当k=10时,将一个完整的数据集划分为平均10个互斥子集。然后依次取其中一个子集作为测试集,其余9个子集的并集作为训练集。最后将数据的每个子集块用于训练和测试,这样可以最大限度地利用数据集,并且最终的验证结果不依赖于训练集的随机选择。
-
评估指标
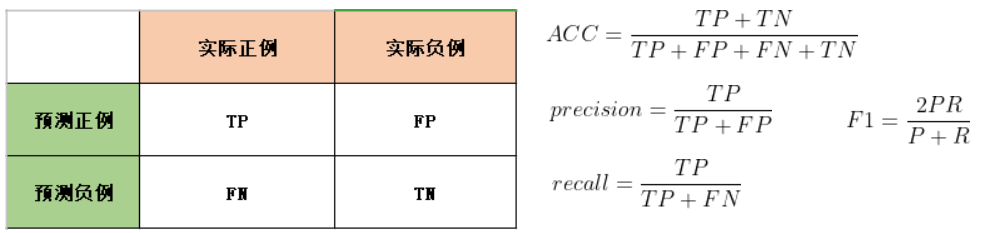
- 有效性:TP表示模型预测为阳性的阳性样本,FP表示模型预测为阳性的阴性样本,FN表示模型预测为阴性的阳性样本,TN表示模型预测为阴性的阴性样本。根据这四个要素可以计算出常用的评估指标,即准确率(ACC)、精确度(Precision)、召回率(Recall)、F1值。此外还有ROC、AUC这些曲线表示的指标,更为直观。
-
时间开销:训练时间是指使用给定的一组训练样本训练流量分析模型所需的时间,而验证时间是指使用预训练模型分析测试集所需的时间。时间复杂度更偏向于评估计算开销。
-
泛化能力:网络中的流量总是不断变化,新的加密协议也在不断出现,当流量特征发生变化后,之前的模型可能不再适用。评估方法为仅使用少量新样本重新训练先前过时训练集训练的模型,其性能表现良好则说明该模型具有较强的泛化能力。
网络资产识别
- 设备指纹
- 从网络安全的角度考虑,当设备接入网络时,网络管理员需要对设备进行认证,并分配合适的权限。但设备多更新频繁,手工认证是不现实的,而且恶意设备可能会以虚假身份响应查询,或者偏离其预期行为。所以需要设备指纹识别来更方便和更安全的管理大量的设备。
- 随着物联网设备的数量和类型不断增加,大多数研究都集中在物联网设备上,同时发生的涉及物联网设备的攻击也在变多。但是大多数物联网设备产生的流量较少,多样性低,这给基于流量的识别带来了困难。传统机器学习方法有采用链路层特征来进行流量表示然后送入RF分类器中,但是这种特征不足以识别所有类型设备;还有利用物联网设备会频繁查询某些特定域名的特点提取出相关特征,并采用滑动窗口的方法进行流量分流,以避免某一活动产生的流量被隔断。
- 机器学习在进行该任务时,存在两个明显缺陷:它们都依赖于人工特征选择,这需要先验的领域知识;它们与特定任务紧密结合,不能轻易转移到不同的任务中。为解决这种限制可以采用深度学习方法,有研究将数据包到达间隔时间序列重塑为二维图像作为流量表示,并使用CNN构建分类器。
......
攻击检测
-
传统的异常检测方法通常基于预先确定的签名扫描数据包内容来发现恶意模式,但是由于加密流量的出现,基于有效载荷的异常检测方法效果变差。
-
恶意软件检测
- 目的是利用流量中反映的独特特征来检测目标软件在执行期间的行为。
- 传统机器学习方法有将从流量中选择的特征输入到集成学习模型中,最终XGboost模型效果最好。但是仅使用现有的特征对于检测未包含在训练集中的未知恶意软件效果不佳,于是有研究提取恶意软件流量中共有的特征,如时间属性和包数,将其作为输入对多种机器学习模型进行训练。有研究提出一种物联网恶意软件检测方法,通过分析流量数据包的序列来发现物联网设备的状态是否与软件声明的状态一致,使用自然语言处理的方法来进行一系列操作,但是NLP分析的过程非常耗时,限制了该方法的能力。
- 由于流量特征的多样性和可变性,传统机器学习已难以胜任。因此,引入深度学习自动特征提取和有效特征学习的关键问题。有研究提出基于CNN和AE的级联模型,该模型以二维图像作为输入。其次,由于流量是由练习的数据包组成的,相邻的数据包之间通常密切相关,而LSTM能够处理顺序输入和处理长期依赖关系,所以非常适合用于流量分析。
-
网络异常检测
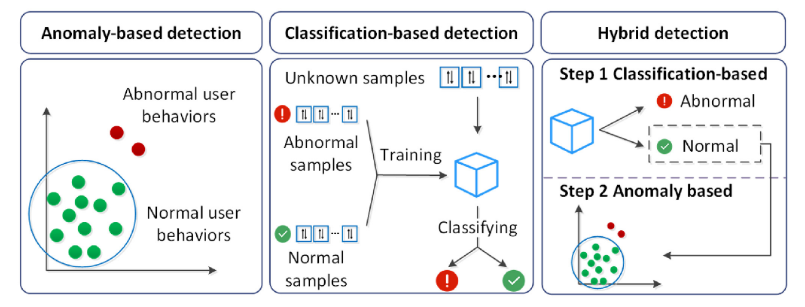
- 基于异常的检测只利用正常流量构建模型,通常使用无监督学习训练,偏离正常模式的行为会被归类为异常。但是这种方法的性能取决于用于训练的正常用户模式是否全面,如果不够全面则会出现较高的误报率。
- 基于分类的检测利用正常流量和异常流量来构建具有监督学习方法的分类器。通常使用聚类算法实现,这种方法增强了检测未知异常的能力,但是如果攻击者能够模仿正常人类用户的行为,则与攻击相关的流量可能会聚集到正常类中。总之,基于分类的检测方法存在固有局限性,即难以处理未知类型的攻击。
- 混合检测是基于异常检测和分类检测的结合。第一步基于分类检测,将这一步中分类为正常的样本作为第二步基于异常检测的输入。结合有监督学习和无监督学习来发现可疑行为,具体来说,有监督机器学习算法用于过滤攻击流量的子集,而无监督机器学习算法用于发现在前一步被错误分类为“正常”的样本。
- 深度学习方法:深度学习可以从原始流量中提取特征。有使用CNN、LSTM、SAE进行异常检测的,相比于机器学习只需要更少的人工干预,更加自动化。有研究将聚类算法与SAE算法结合,用于检测DDoS攻击,对于每个时间间隔,提取8种类型的特征,如具有不同TCP标志的数据包的百分比,作为聚类和SAE模型的输入,采用聚类算法建立正常用户行为模型,将偏离正常用户行为划分为DoS攻击。SAE用于检测能够模仿普通人类用户浏览行为的攻击,这是聚类算法无法发现的。
- 基于异常的方法更适合发现未知的零日攻击,适合于现实网络环境中。
未来方向
-
尽管开发加密流量分析方法方面已经较为成熟,但在数据集构建、流量表示、分析模型构建和
潜在对策(防御分析的方法)方面仍存在重大挑战 -
高质量数据集应当有以下两个特点:首先,数据集的样本应当充足并且多样,如训练数据集应当包含不同web浏览器在不同设备上访问众多网站产生的实例,并且通过不同入网方式访问互联网;其次,为了判定分类器的正确性和有效性,数据集中的数据应当能够通过直接观察获得真实标签。
-
统计特征常常被输入到传统的机器学习分类其中,而定向数据包序列、流量编码为图像、流量编码为图、频域被提出用于深度学习分类器。为了便于对不同类别的加密流量进行分类或聚类,有效的表示应该具有足够的判别性,使每个类别能够轻松地相互分离。更具体地说,强大的表示应该使流量实例与同一类中的流量实例相似,而与不同类中的流量实例不同。
-
此外,流量表示应当具有良好的鲁棒性,统计特征通常对协议升级造成的变化很敏感,这会导致很小的变化就使得效率低下。而流表示(序列、图像、图)对这些变化更健壮。
-
时间效率高的流量表示现在依旧是一项挑战,统计特征通常需要对熵和频谱进行复杂的计算,其时间效率较差;而流表示的时间效率取决于表示的具体形式,例如,基于序列和基于图的表示很容易从原始加密流量中获得,而基于图像的表示会导致将数据包序列信息转换为图像结构的时间开销急剧增加。
-
使用深度学习模型提取有效特征,然后用于训练传统的机器学习分类器是一个新兴的趋势。