Revolutionizing Encrypted Traffic Classification with MH-Net: A Multi-View Heterogeneous Graph Model--2025
随着网络安全问题的日益重要,加密流量的分类问题已成为一项紧迫的挑战。传统的基于字节的流量分析方法受到信息粒度的严格限制,不能充分利用字节之间的多种相关性。为了解决这些限制,本文介绍了MH-Net,这是一种用于网络流量分类的新方法,它利用多视图异构流量图来模拟流量字节之间的复杂关系。mh - net的本质是将不同数量的流量位聚合成多种类型的流量单元,从而构建具有不同信息粒度的多视图流量图。通过考虑不同类型的字节相关性,如报头-有效载荷关系,MH-Net进一步赋予流量图异质性,显著提高模型性能。值得注意的是,我们采用多任务方式的对比学习来增强学习到的交通单元表示的鲁棒性。在ISCX和CIC-IoT数据集上对包级和流级流量分类任务进行的实验表明,与数十种SOTA方法相比,MH-Net的总体性能最好。
引言
-
VPN和tor等加密技术是一把双刃剑,它们可以保护用户隐私,但是也会成为攻击者隐藏其身份的工具。传统的数据包检测技术DPI对于加密流量已经失效
-
过去几年中,人们提出了许多增强加密流量分类技术的能力。
- 基于统计的方法是依赖于手工制作的流量统计特征,然后利用传统的机器学习模型及逆行分类,但是需要大量的特征工程,并且容易受到不可靠流的影响
- 后来有使用深度学习模型进行流量分类,如预训练语言模型、神经网络等。它们具有性能的提升,但是未能揭示流量字节之间的细粒度相关性。这可归因于以下两个缺点
- (1)受字节约束的刚性信息粒度。大多数现有方法默认将字节视为不可分割的单位,这忽略了交通数据中包含的不同粒度的信息。举个实际的例子,一个汉字用两个字节表示,而一个英文字符只用一个字节表示,说明流量数据普遍包含不同粒度的信息(注意粒度不一定是字节(bytes),也可能是位(bits))。
- (2)缺乏对字节间多种关联类型的考虑。目前的方法将字节序列中不同位置的字节的相关性混合在一起,忽略了也没有利用不同类型的相关性之间的差异(例如header中的字节与payload中的字节之间的相关类型不同)
-
为了解决上述(1)的缺陷,MH-Net模型首次将不同数量的流量比特(bit)聚合为多种类型的流量单元(traffic units)。例如,构建4比特单元和8比特单元。这种多粒度的流量单元设计有助于捕捉流量数据中不同粒度的信息,从而提高模型对流量数据的理解能力;为解决上述(2)的缺陷,MH-Net 使用 点互信息 将不同类型的流量单元序列转换为多视图流量图,MH-Net 引入了三种类型的单元相关性,分别是:报头-报头、报头-负载、负载-负载。
相关工作
-
流级分类任务
-
基于统计特征的方法:许多方法使用统计特征来表示数据包属性,并利用传统的机器学习模型进行分类。
-
基于指纹匹配的方法:指纹即流量特征,用于流量分类。FlowPrint (van Ede et al. 2020)通过创建计算目标ip之间活动值的关联图来生成流量指纹。
-
基于深度学习的方法:深度学习具有强大的学习能力。et - bert (Lin et al. 2022)在大规模交通数据集上进行预训练任务,以学习强大的原始字节表示,这既耗时又昂贵 ;YaTC (Zhao et al. 2023)采用基于掩码自编码器的流量转换器,在提高性能的同时实现高效的特征提取。
-
-
报文级分类任务
- 可以识别网络中每个报文的不同类别
- 之前有将数据包字节作为像素值,然后转换为图像,再将图像反馈到2D-CNN和3D-CNN中进行数据包分类;还有利用cnn和自动编码器提取字节特征的;et-bert需要进行两次独立的训练和微调,这在计算上是昂贵的;总之,现有方法在及逆行流分类任务时没有充分考虑原始字节中包含的信息相关性,导致面临性能瓶颈。
本文方法
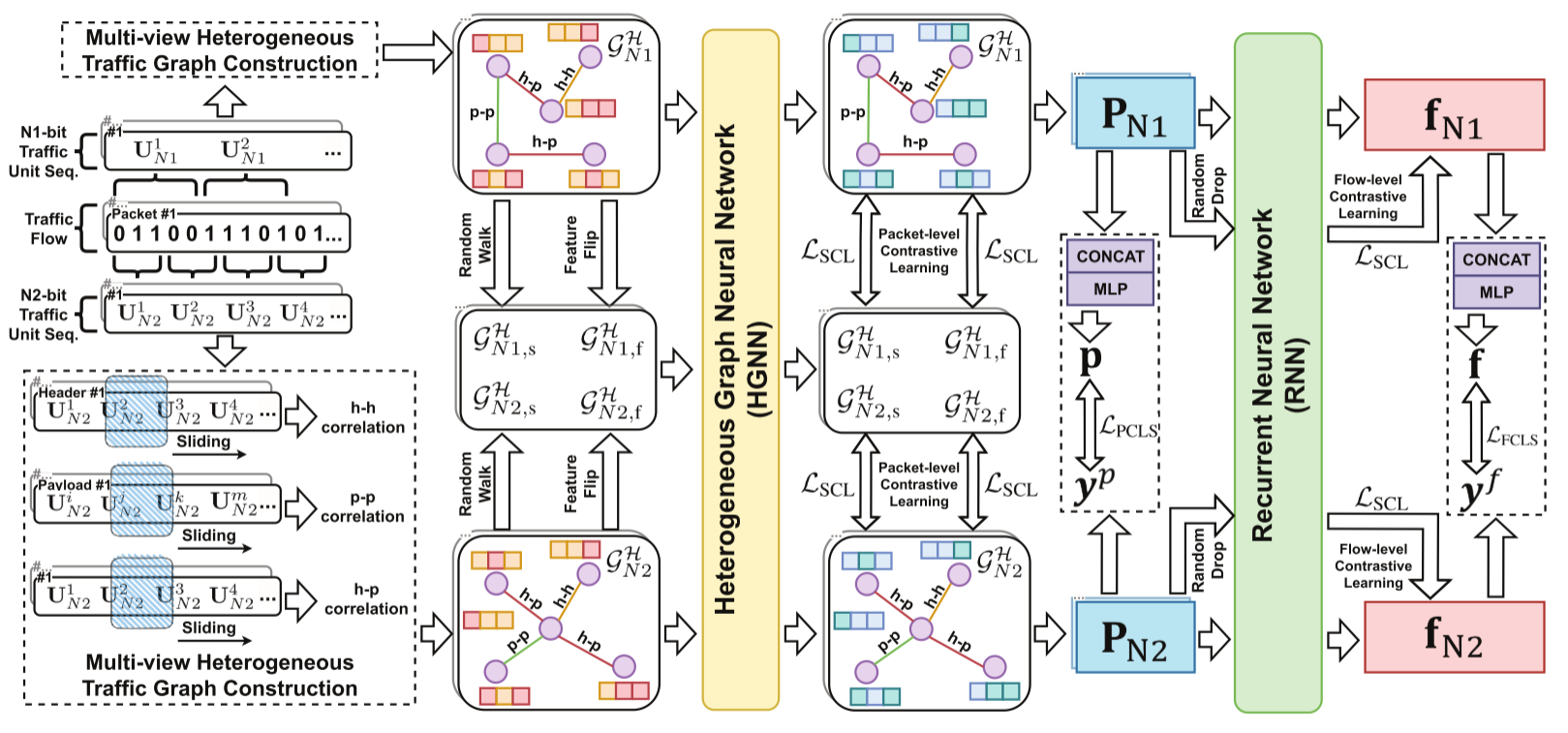
1.多视图流量图结构
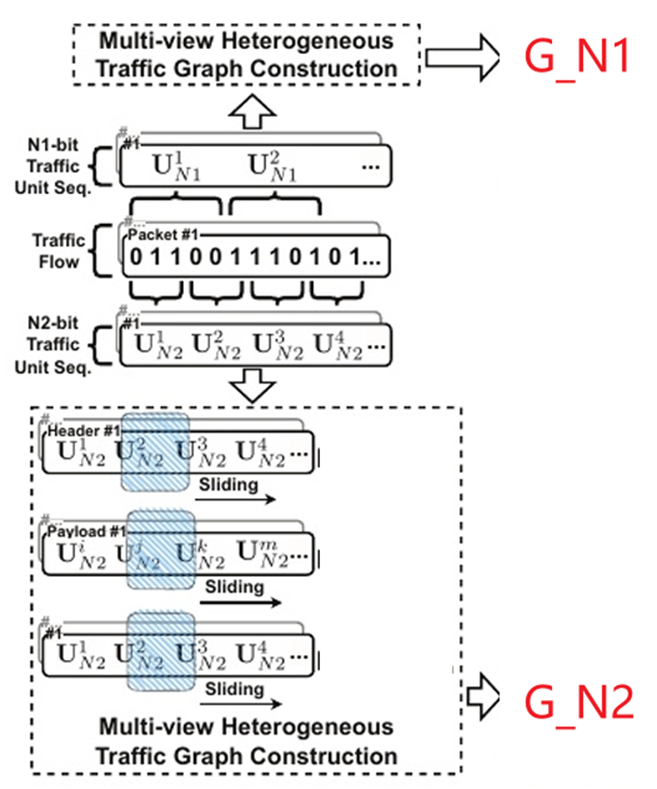
-
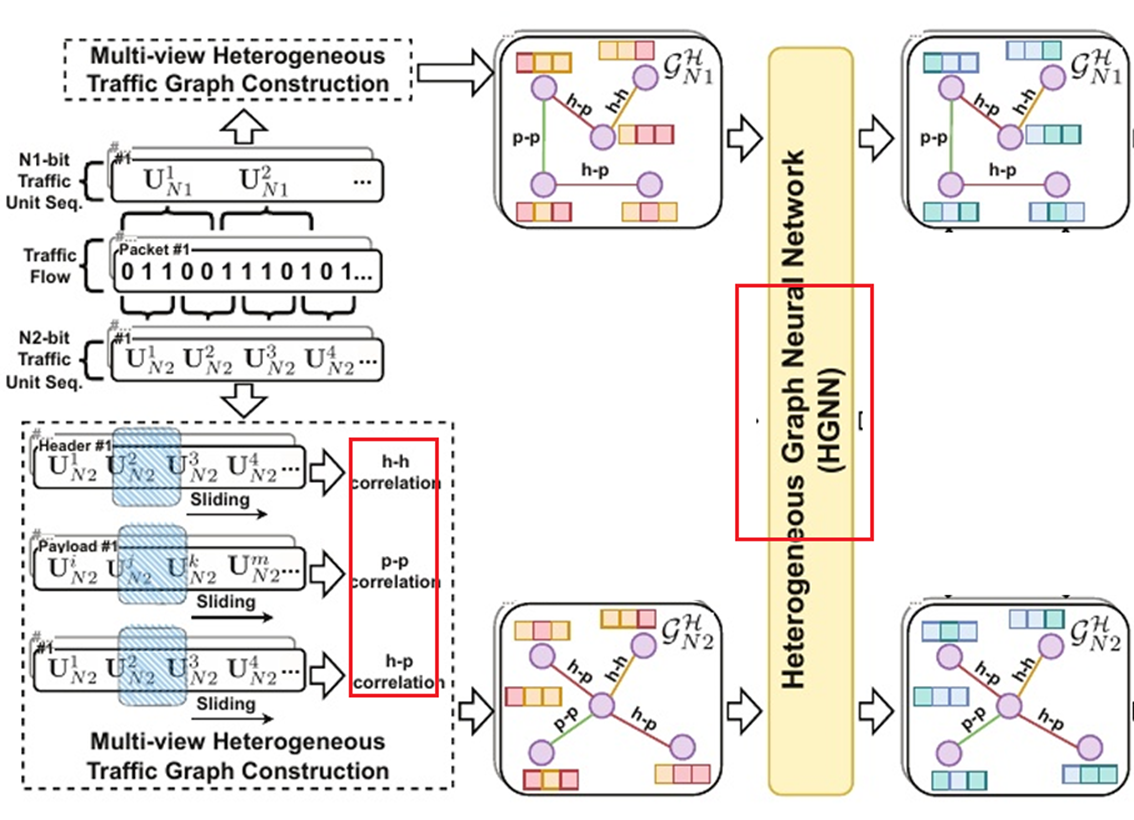
作者将不同长度的原始数据比特聚合到各种流量单元中,得到不同粒度的流量单元。但是,这些流量单元仍然是分散的个体,不利于挖掘一系列流量单元之间的潜在关系。所以,作者进一步将流量单元序列转化成流量图,使其成为一个相互关联的整体。作者使用滑动窗口在流量单元序列上计算两个单元同时出现的频率和每个单元出现的频率来计算PMI。利用逐点互信息(PMI)来量化流量单元之间的相关性。


2.异构流量图表示
-
由于报头和有效载荷的功能不同,导致存在信息异构性。所以作者根据流量单元在流量序列中的位置,提出三种类型的流量单元相关性,即报头-报头、报头-负载、负载-负载。并将PMI算法分别应用于报头、有效载荷 和报头+有效载荷(即整个流量单元序列)的流量单元序列, 以获得三种类型的流量边,将其进一步集成到异构流量图中。经过该过程,$G{N1}$和$G{N2}$转换为多视图异构流量 图$G{N1}^H$和$G{N2}^H$
-
报头-报头(h-h)相关性:报头部分通常包含数据包的元数据,如源地址、目标地址、协议类型等。虽然一个数据包中只有一个报头,但报头中的不同字段之间存在内在的相关性。例如,源地址和目标地址可能与特定的网络行为相关联,协议类型可能与数据包的用途相关。这种相关性反映了报头字段之间的逻辑和功能联系。
-
报头-负载(h-p)相关性:报头和负载部分的功能不同,报头是元数据,而负载是实际传输的内容。报头中的信息(如协议类型、端口号等)可以为理解负载内容提供上下文。例如,某些协议可能用于特定类型的应用程序数据,报头中的信息可以帮助解释负载的内容和用途。
-
负载-负载(p-p)相关性:负载部分包含实际传输的数据,这些数据在逻辑上可能具有内部结构和相关性。例如,负载中可能包含特定格式的数据(如HTTP请求、文件传输内容等),这些数据之间存在语义或格式上的联系。
-
-
对于上述过程获得的每个数据包的流量图,进一步送到异构图编码器中进行流量表示。具体方法为使用异构图神经网络(HGNN)来提取流量图的判别特征。
3.MH-Net多任务训练
-
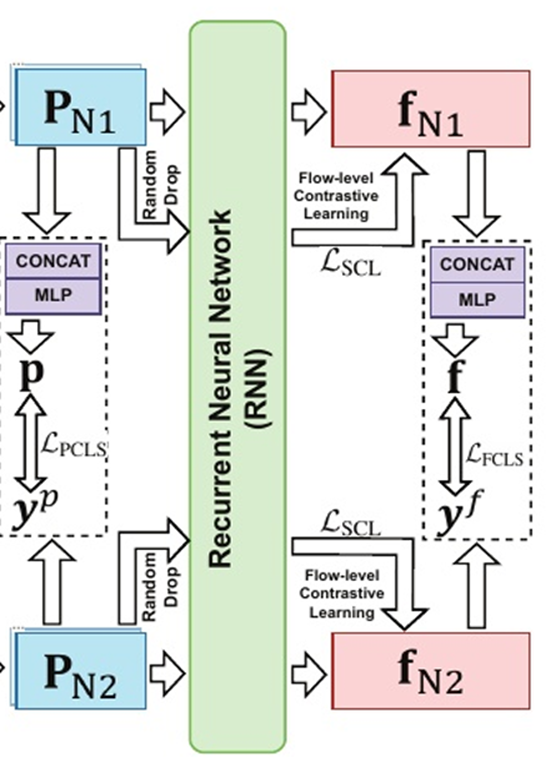
使用多任务的方式训练MH-Net,从而更好地优化。训练目标主要包括流量分类和对比学习任务。
-
流量分类任务:在这个任务中同时进行流级和包级地流量分类任务
-
双层对比学习:目的是通过对比来自各种数据增强的正样本对(由同一个数据的不同增强版本组成,它们在语义上是相似的)和负样本对(由不同数据的样本组成,它们在语义上是不相似的)来学习语义不变表示,从而增强模型的多视图数据包级和流级流量表示。
-
流级对比学习:通过随机丢包生成增强的流量流,从而构造正样本对,从其他流量流中采样生成负样本对,目标是学习流量流的鲁棒表示,使得模型能够识别不同流量流之间的差异。
-
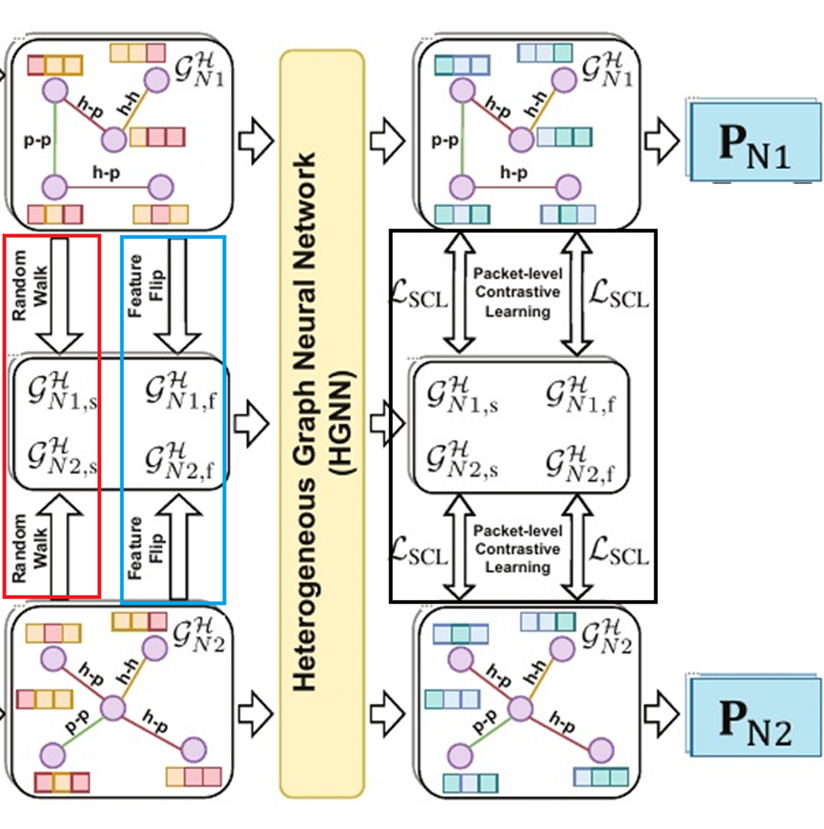
包级对比学习:由于数据包级流量表示是基于流量图派生的,因此需要生成增强图以进行进一步的对比学习,目的是为了获取对比学习所需要的正样本对。
- 图结构增强:•对于图结构增强,利用随机行走算法该算法首先随机选择一个节点,并迭代地对其邻居进行随机遍历,以获得增强的流量图$G_{Hi,s}^H$。
- 节点特征增强:对于节点特征增强,通过翻转其节点特征(例如将二进制数据的0翻转为1)增强流量图,从而产生另一个增强的流量图$G_{Hi,f}^H$
整体结构
-
模型整体损失函数计算方法:
- 其中,$L{PCLS},L{FCLS},L{PCL},L{FCL}$ 分别表示包级分类损失、流级分类损失、包级对比损失、流级对比损失
-
理解:对于每个数据包都进行不同粒度的划分,获得不同粒度的流量单元,构成多个流量图,即多视图。这些划分的流量单元在图中就是节点,通过PMI计算的三种异构相关性即图中的连接节点的边。然后使用异构图神经网络(HGNN)对异构流量图进行特征提取,从而充分利用流量数据中的异构性。然后进行对比学习,目的是增强模型的鲁棒性和对流量数据的理解能力。HGNN提取的特征仅为每个单独数据包的特征,将其作为RNN的输入,利用RNN能够捕获时间依赖性的特点,并且还捕获了数据包之间的顺序关系,将包级特征聚合为流级特征,最后通过一个多层感知机MLP进行分类,从而能够同时实现包级和流级流量分类任务。

实验
-
数据集:CIC-IoT(2022)、ISCX VPN-NonVPN(2016)、ISCX Tor-NonTor(2017) 共五个数据集。训练:测试=9:1
-
实验中使用4bit和8bit流量单元来构建多视图异构流量图
-
模型在包级和流级分类任务上的表现(对比试验)
- 流级分类:在CIC-IoT和ISCX数据集上本文的模型效果最好。由于从分利用了流量字节而不是统计特征,效果远超统计特征方法,并优于其他的深度学习方法。ET-Bert方法效果不错,但是计算开销大的吓人。
- 包级任务:本文模型Mh-Net具有绝对优势,原因仍是该模型充分利用流量字节间的信息相关性。
-
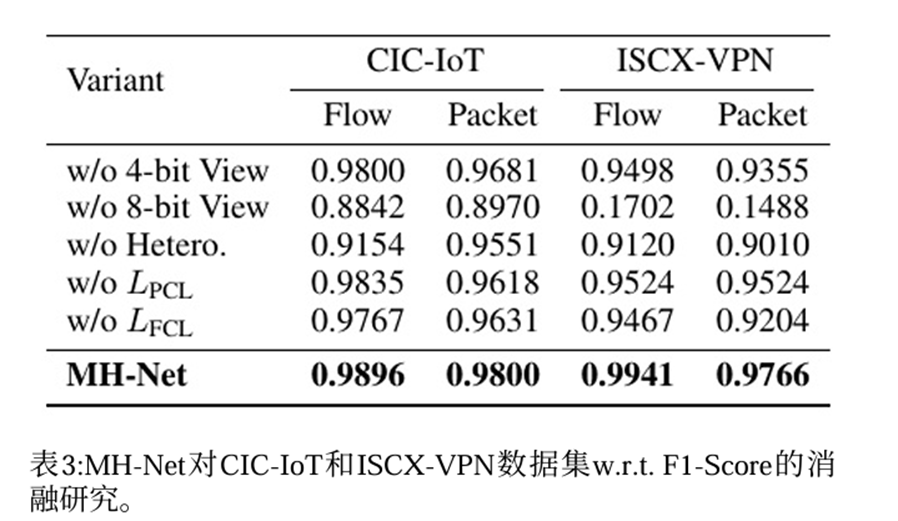
模型中每个模块对模型性能的贡献(消融实验)
- 实验对比了完整模型、移除4-bit(w/o 4-bit View)、移除8-bit(w/o 8-bit View)、移除异构相关性(w/o Hetero)、移除报文级别对比学习(w/o LPCL)、移除流级别对比学习(w/o LFCL)。
- 8bit流量单元比4bit流量单元对模型性能的贡献更大,但是4bit所携带的信息同样重要。移除 报头-报头、报头-负载、负载-负载 三种相关性后效果显著下降,说明异构相关性起到重要作用。对比学习也起到一定作用。
-
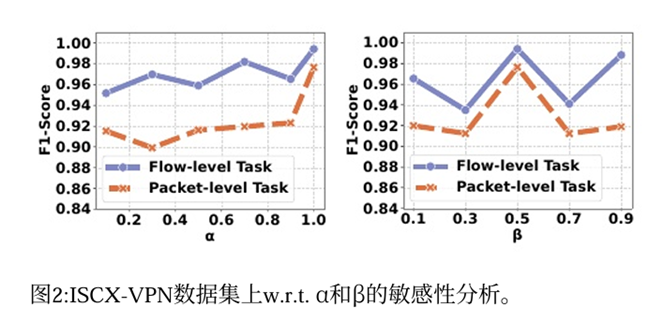
模型对超参数敏感吗
- 文中对超参数α和β进行了测试,α 控制包级对比学习任务的权重、β 控制流级对比学习任务的权重。结果表明模型对α更敏感,说明包级对比学习的有效性,β为0.5时模型效果最好。
-
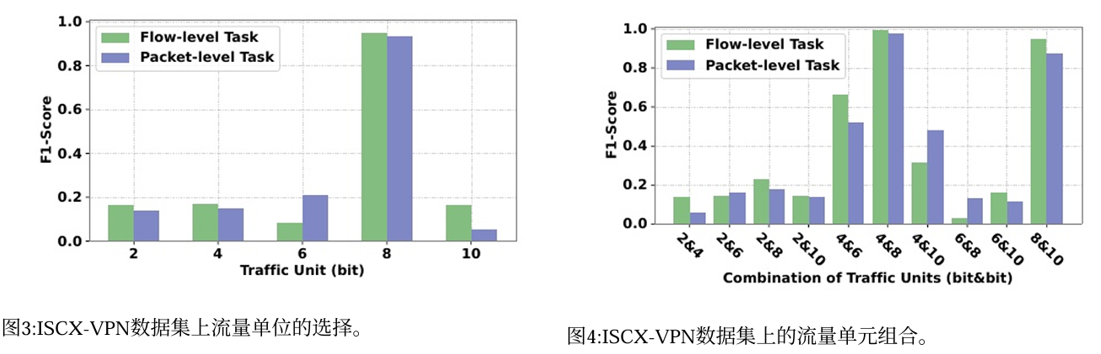
流量单元的选择和组合如何影响性能
- 8bit流量单元效果最好,其他流量单元效果差得多。4bit和8bit组合最好,与单个流量单元相比,组合的效果更好。这意味着具有不同信息粒度的流量单元之间可能存在信息互补性和干扰之间的权衡,这可以潜在地用于进一步提高模型性能。