Linux命令行与shell脚本大全
第一部分
1.Linux系统基础
-
Linux系统内核、GNU实用工具(shell就包含在CNU实用工具中)、图形桌面环境经过打包共同组成Linux发行版,如Redhat、Debian等。基于这些核心发行版,后来衍生出一些特定用途的发行版,如centos是基于Redhat的,Ubuntu基于Debian
-
Linux系统内核用于管理系统内存、软件程序、硬件设备、文件系统。
- 内核可以管理实际的物理内存,还能创建并管理虚拟内存。内核通过硬盘上称为交换空间(swap space)的存储区域来实现虚拟内存。内核在交换空间和实际的物理内存之间反复交换虚拟内存中的内容。这使得统以为自己拥有比物理内存更多的可用内存
- 内核中的第一个进程(init进程)用于启动系统中所有的其他进程,如systemd
- 驱动程序是应用程序和硬件设备的中间人,实现了内核与设备之间交换数据,Linux系统将硬件设备视为一种特殊文件,即设备文件,分为三种,字符、块、网络设备文件。
- Linux系统能够去写其他操作系统的文件系统。
-
图形化桌面系统中的终端是仿真终端
-
使用
man、info、help查看命令的使用方法
2.文件系统
-
Linux大多使用日志文件系统,这种系统不同于以往的ext2(将数据直接写入存储设备再更新i节点),这种系统先将文件变更写入临时文件(称作日志)。在数据被成功写到存储设备和 i 节点表之后,再删除对应的日志条目,这样即便系统崩溃或断电系统依然能够通过读取日志文件处理未提交的数据 。
-
Linux的文件系统采用虚拟目录,其目录结构只包含一个称为根目录
/的基础目录,其他的所有文件和目录都在根目录之下。虚拟目录的结构并不与实际的物理磁盘结构相同,不像Windows文件系统中会明确标识文件路径在哪个盘符下。 -
可以存在一块磁盘与根目录关联,而另一块磁盘挂载到/home目录的情况
-
常用的目录含义
/:虚拟目录的根目录,通常不会在这里放置文件/bin:二进制文件目录,存放了很多用户级的GNU实用工具/dev:设备目录,Linux 在其中创建设备节点/etc:系统配置文件目录/home:主目录,Linux 在其中创建用户目录(可选)/lib:库目录,存放系统和应用程序的库文件/opt:可选目录,存放第三方软件包/tmp:临时目录,可以在其中创建和删除临时工作文件/usr:用户目录,一个次目录层级结构(secondary directory hierarchy)/var:可变目录,存放经常变化的文件,比如日志文件
-
链接文件是 Linux 文件系统的一个优势。如果需要在系统中维护同一文件的两个或多个副本,可以使用单个物理副本加多个虚拟副本(链接)的方法代替创建多个物理副本。Linux中有两种类型的文件链接
-
符号链接(软链接):这是一个实实在在的文件,即是一个独立的文件,该文件中的内容用于指向存放在虚拟目录结构中某个地方的另一个文件,相当于“快捷方式”或“指针”。该文件的内容与所链接的文件的内容并不相同。
lrwxrwxrwx. 1 christine christine 9 Mar 4 09:46 slink_test_file -> test_file -
硬链接:创建一个独立的虚拟文件,其中包含了原始文件的信息和位置,但是二者根本而言是同一个文件。相当于给同一个文件起了另一个名字,硬链接与目标文件的inode相同,即它们指向的是同一块磁盘上的数据
$ ls -li *test_one 1415016 -rw-rw-r--. 2 christine christine 0 Feb 29 17:26 hlink_test_one 1415016 -rw-rw-r--. 2 christine christine 0 Feb 29 17:26 test_one # 两个文件的inode编号相同,说明是同一个文件 -
当删除目标文件时,由于软链接指向的目标被删除,软链接就会失效,成为“死链接”,而只要至少还有一个硬链接指向该 inode,文件数据就不会被真正删除。只有当所有指向该 inode 的硬链接都被删除后,文件数据才会被释放。
-
-
mv移动文件不会改变inode编号和时间戳,其只是改变文件名和位置 -
file命令可以查看文件类型,包括目录、文本、链接文件、脚本文件等,并且能够确定二进制可执行程序编译时面向的平台和所需的库 -
head命令无法像fail命令一样使用-f参选项来实时监控文件的变化内容。
3.shell命令基础
-
在shell命令行中输入并执行
bash、dash都可以创建一个子shell,在子shell中也可以创建下一个子shell,子shell的父进程ID即PPID为父shell的PID。可以通过exit命令退出子shell,当在最上层的shell中执行exit时为注销。 -
将许多命令以分号分隔可以一次性执行一系列命令,将这些命令以分号分隔的方式放入圆括号内则为进程列表,它会生成一个子shell来执行这些命令,将命令放入花括号中为命令分组,不会创建子shell
# 一次性执行一系列命令 $ pwd ; ls test* ; cd /etc ; pwd ; cd ; pwd ; ls my* # 进程列表 $ (pwd ; ls test* ; cd /etc ; pwd ; cd ; pwd ; ls my*) # 命令分组 $ {pwd ; ls test* ; cd /etc ; pwd ; cd ; pwd ; ls my*} -
然而子shell会消耗更多的系统资源,且其并非正真的多进程处理,原因是终端与子shell的I/O绑定在了一起,这导致如果子shell没有执行完毕将结果输出到终端则会阻塞。
-
后台模式:在命令末尾加上字符&可以把进程置于后台运行
me@debian: /$ sleep 3000& [1] 1026 # 1是后台作业号,1026是后台作业的进程ID me@debian: /$ ps -lf F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD 0 S me 990 989 0 80 0 - 2044 do_wai 13:00 pts/0 00:00:00 -bash 0 S me 1026 990 0 80 0 - 1418 hrtime 13:20 pts/0 00:00:00 sleep 3000 0 R me 1027 990 99 80 0 - 2834 - 13:20 pts/0 00:00:00 ps -lf #jobs命令可以查看后台作业信息 me@debian: /$ jobs -l [1]- 1026 运行中 sleep 3000 & [2]+ 1027 运行中 sleep 1234 & -
协程:协程同时做两件事,一是在后台生成一个子 shell,二是在该子 shell 中执行命令。
# 创建一个协程 $ coproc sleep 10 # 创建并命令为My_Job,注意花括号与命令间的空格 $ coproc My_Job { sleep 10; } -
外部命令在执行时会创建一个子进程,称为衍生,外部命令通常位于
/bin、/usr/bin、/sbin、/usr/sbin目录中,ps就是外部命令。内建命令执行时不会创建子进程,这种命令与shell编译为一体,作为shell的组成部分存在,可以通过type命令判断某个命令是否内建。内建命令执行速度更快,效率更高。me@debian: /$ type cd cd 是 shell 内建
4.环境变量
-
设置变量时,变量名与等号、等号与值之间不能存在空格。如果字符串中存在空格,应使用单引号或者双引号包裹起来。
my_variable=Hello my_variable="Hello World" -
export命令可以将变量设置为全局变量(也称为导出),在子进程和父进程中均可用,在子进程中改变全局变量的值不会影响父进程环境中该变量的值。在子进程中删除全局变量同样如此。 -
当登录Linux时,bash shell 会作为登录 shell 启动。登录 shell 通常会从 5 个不同的启动文件中读取命令。
/etc/profile:系统默认的bash shell的主启动文件,每个用户登录时都会执行这个启动文件,该文件内容为迭代/etc/profile.d目录下的所有文件$HOME/.bash_profile$HOME/.bashrc$HOME/.bash_login$HOME/.profile
-
环境变量持久化:临时在终端设置的变量在注销或重启后会消失。可以将全局环境变量设置在/etc/profile文件中,但是每当升级系统时,该文件都会随之更新,导致环境变量消失。建议的做法为在/etc/profile.d目录中创建一个以.sh 结尾的文件。把所有新的或修改过的全局环境变量设置都放在这个文件中。
-
数组变量的设置可以直接通过在圆括号里放置以空格为间隔的值来完成。
unset 数组名可以直接删除整个数组。数组变量在shell脚本编程中不常使用。
5.文件权限
-
系统中用户权限是通过创建用户时分配的用户 ID(user ID,UID)来跟踪的。/etc/passwd文件中保存着用户相关的信息。Linux系统服务器后台的服务最好使用该服务自己的账号登录,且不应当是root权限,这样即便某个服务被攻破也无法直接获得系统的访问权限。
-
/etc/passwd文件中各个字段的含义root:x:0:0:root:/root:/bin/bash bin:x:2:2:bin:/bin:/usr/sbin/nologin sys:x:3:3:sys:/dev:/usr/sbin/nologin sync:x:4:65534:sync:/bin:/bin/sync 登录用户名:密码:用户UID:组ID:备注:$HOME目录位置:用户默认shell # /etc/passwd中密码都被设置为x即不可见,用户密码被单独保存在/etc/shadow文件中(通常) -
useradd用于添加用户,-D选项可以修改系统默认的新用户设置。userdel用于删除用户,但是默认情况下只删除/etc/passwd 和/etc/shadow 文件中的用户信息,属于该账户的文件会被保留,-r选项可以删除用户的$HOME目录以及邮件目录。 -
文件权限如图
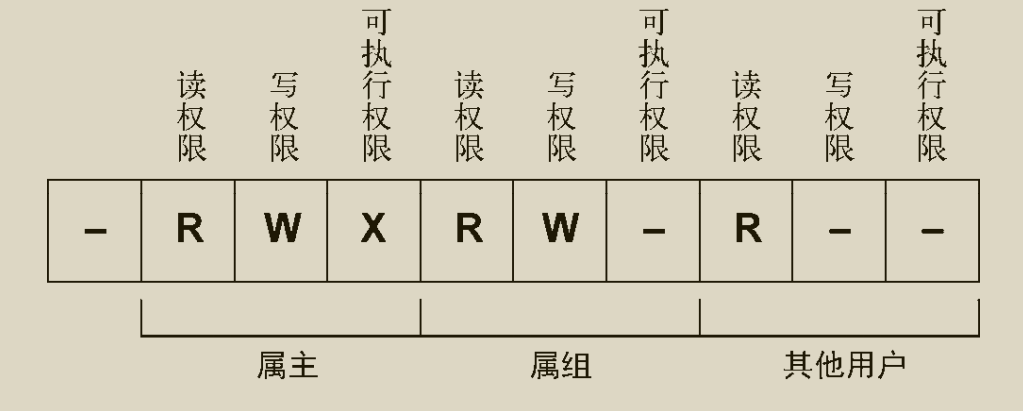
-
chmod更改文件权限,chown更改文件属主也可以更改属组,chgrp更改文件属组。三者在使用时文件名都是第二个参数,要更改为的权限是第一个参数。 -
文件共享
-
将共享文件的用户设置同一个组,并将该组作为文件的默认属组
-
SUID权限(危险!):设置该权限可以轻松地共享文件,而不再需要为共享的用户再设置同一个组。该权限使得任何用户执行该文件时,程序会以文件属主的权限运行。所以当/bin/bash被设置s权限时,任意用户都可以轻松提权。
-
SGID:对文件而言,程序会以文件属组的权限运行;对目录而言,该目录中创建的新文件会以目录的属组作为默认属组。SGID 位对文件共享非常重要。启用 SGID 位后,可以强制在共享目录中创建的新文件都属于该目录的属组,这个组也就成了每个用户的属组。
-
粘滞位:应用于目录时,只有文件属主可以删除或重命名该目录中的文件。
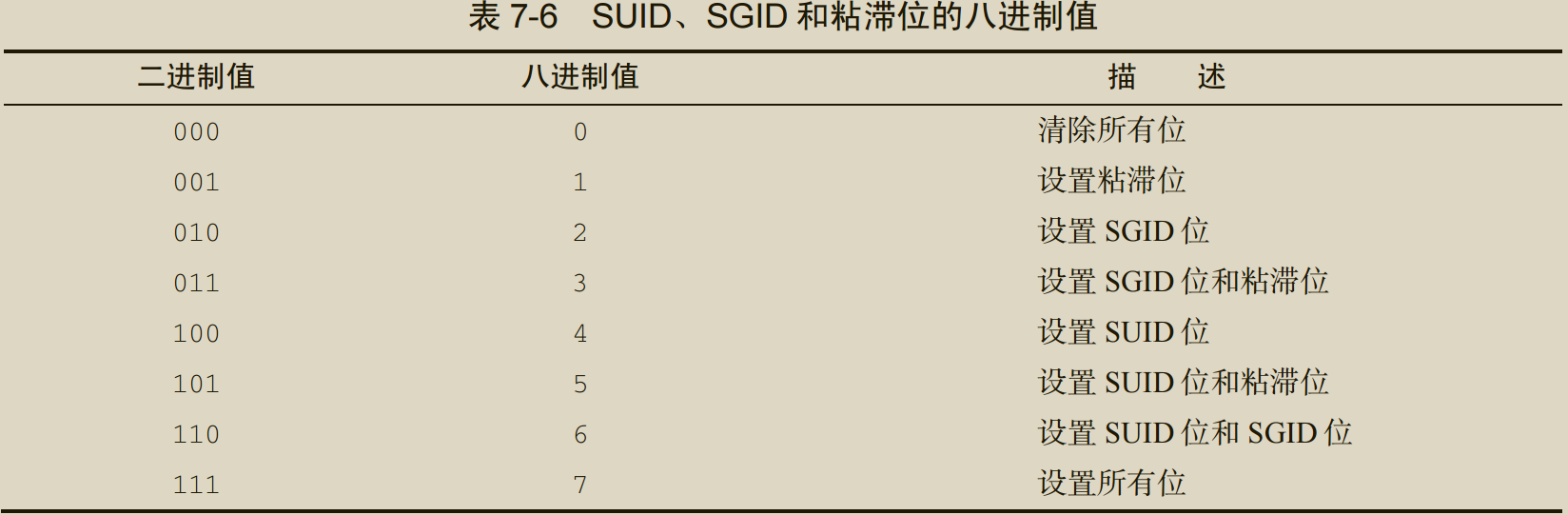
-
第二部分
1.shell脚本基础
-
shell文件中的第一行遗憾会指定要使用的shell,使用
#!号开头,#再shell中表示注释,然而,shell脚本文件的第一行是个例外,#后面的惊叹号会告诉 shell 用哪个 shell 来运行脚本。#!/bin/bash -
shell脚本中,引用变量值时需要加
$,对变量赋值时不需要加$ -
使用
``或$()包裹命令可以将命令的执行结果赋值给变量 -
重定向
>会覆盖原有的内容,>>会将内容追加到文件中<输入重定向,常用作从文件获取输入。<<内联输入重定向,用来将输入重定向到一个交互式 Shell 脚本或程序。
-
expr、$[]、bc、(())都可以用于数值计算,但是前两种只能计算整数,bc可以用于浮点数计算,双括号支持更多的计算符号。# 使用expr计算时,容易被shell误解的符号需要转义 var1=expr 5 \* 2# 使用$[]更简单,且无需担心符号被shell误解 var1=$[5 * 2] # 设置scale为4,可以让计算结果保留四位小数,scale默认为0 var1=$(echo " scale=4; 3.44 / 5" | bc) # 双括号还可以用在if和for的条件判断中,从而实现类似于C语言风格的语法 (( var1 = 2 ** 2 )) -
if-then条件判断语句判断的是if后面的表达式的退出状态码,为0则执行then后面的语句。可以使用test命令来测试其他条件,test命令中列出的条件成立时会退出并返回状态码0在shell中,默认任何语句成功执行时,他的退出状态码为0,即$?为0
-
IFS是shell中用于区分字符串分隔的环境变量,可以更改这个变量进行不同的分隔
# changing the IFS value IFS.OLD=$IFS IFS=$'\n' for entry in $(cat /etc/passwd) do echo "Values in $entry –" IFS=: for value in $entry do echo " $value" done done -
循环控制
- break:直接使用break跳出当前循环,使用break 2会跳出下一级的外层循环
- continue:中止某次循环并执行下一次循环,同样可以使用continue 2继续执行外层循环
-
在循环结构语句的
done后加上重定向或者管道,会将循环的所有输出进行指定的操作。例如done > file会将循环的所有输出重定向到文件中,而不会再输出到终端;done | sort会将循环的所有输出经过排序后再打印到终端。 -
shell脚本中花括号里面的变量的
$要改为!,如${!var1},这种做法称为简介引用var2="some_value" var1="var2" echo ${!var1} # 这将输出 "some_value"
2.读取参数
-
getopt:将用户输入解析为程序易识别的形式,在getopt的参数后加冒号表示该选项需要一个参数。这个命令无法读取用户输入的带空格的参数,即便使用引号包裹,它也会将其视为多个参数。
#!/bin/bash # Extract command-line options and values with getopt # set -- $(getopt -q ab:cd "$@") # echo while [ -n "$1" ] do case "$1" in -a) echo "Found the -a option" ;; -b) param=$2 echo "Found the -b option with parameter value $param" shift;; -c) echo "Found the -c option" ;; --) shift break;; *) echo "$1 is not an option" ;; esac shift done # echo count=1 for param in $@ do echo "Parameter #$count: $param" count=$[ $count + 1 ] done exit -
getopts:每次只处理一个检测到的命令行参数,在getopts参数前加冒号表示不显示错误信息,在字母后面加冒号表示该选项需要一个参数。可以识别连写的选项和带空格的参数。
#!/bin/bash # Extract command-line options and values with getopts # echo while getopts :ab:c opt do case "$opt" in a) echo "Found the -a option" ;; b) echo "Found the -b option with parameter value $OPTARG";; c) echo "Found the -c option" ;; ' *) echo "Unknown option: $opt" ;; esac done exit -
read:程序开始运行后用于弹出提示让用户输入。
# 基础用法,用户输入的值将被存储到$age变量中 read -p "Please enter your age: " age # 如果不指定变量,则会将接收的值存储到$REPLY环境变量中 read -p "Enter your name: " echo "Hello $REPLY, welcome to my script." # 无显示读取, -s选项 read -s -p "Enter your password: " pass # 从文件中读取可以使用cat cat $HOME/test.txt | while read line do ... done
3.脚本控制
-
Linux信号
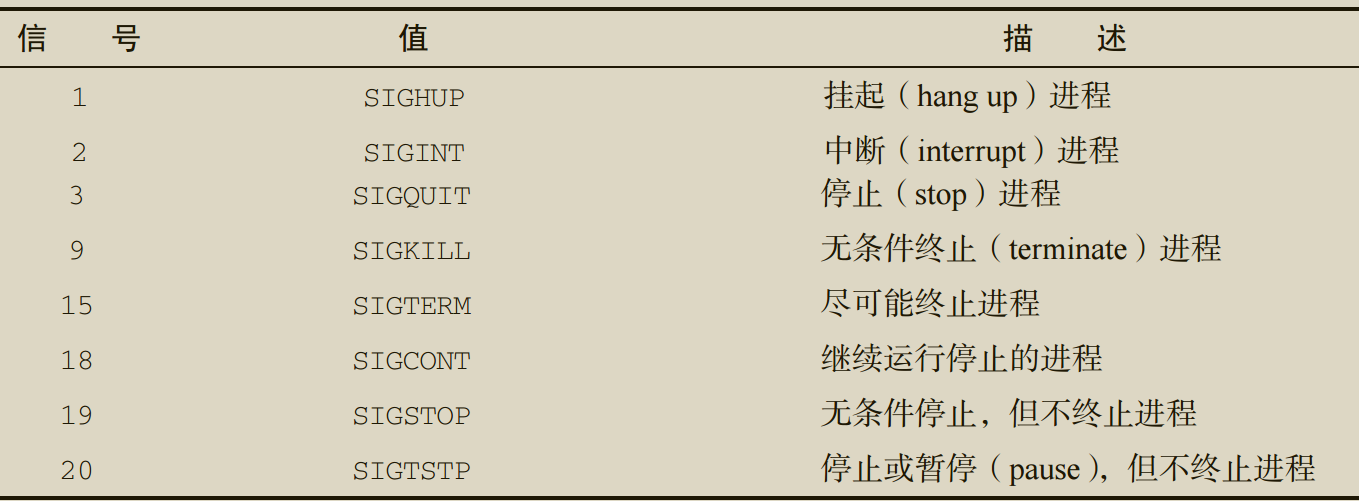
-
当shell收到SIGHUP信号时(比如在离开交互式 shell 时),bash shell会退出,并且在退出之前,它会将 SIGHUP 信号传给所有由该 shell 启动的进程,包括正在运行的 shell 脚本。
-
Linux允许Ctrl+C 组合键会生成 SIGINT 信号,并将其发送给当前在 shell 中运行的所有进程。Ctrl+Z 组合键会生成 SIGTSTP 信号,停止 shell 中运行的任何进程。
-
捕获信号:trap命令
# 每次侦测到 SIGINT 信号时, trap 命令会显示一行简单的文本消息。捕获这些信号可以阻止用户通过组合键 Ctrl+C 停止脚本 trap "echo ' Sorry! I have trapped Ctrl-C'" SIGINT # 捕获脚本退出 trap "echo Goodbye..." EXIT # 移除信号捕获,移除后再使用单连字符可以恢复 trap -- SIGINT -
在后台模式中,进程运行时不和终端会话的 STDIN、STDOUT 以及 STDERR关联。在脚本名后面加上
&就可以让脚本在后台运行。后台进程运行时,它仍然会使用终端显示器来显示 STDOUT 和 STDERR 消息。如果终端会话(pts/0)退出,那么后台进程也会退出。 -
使用
nohup命令可以让脚本忽略关闭终端会话时发出的SIGHUHP信号,脚本可以一直运行。 -
如果作业被停止,可以使用
bg [作业号]让其在后台重启,fg [作业号]让其在前台重启
4.其他
-
mktemp命令可以在本地目录中创建一个临时文件,需要指定文件名模板,文件名末尾要加上6个X
$ mktemp testing.XXXXXX testing.UfIi13 # -t可以强制mktemp 命令在系统的临时目录中创建文件 $ mktemp -t test.XXXXXX /tmp/test.xG3374 -
tee命令能将来自 STDIN(标准输入) 的数据同时送往两处。一处是STDOUT(标准输出),另一处是 tee 命令行所指定的文件名。需要向文件中追加时使用-a选项。
$ date | tee testfile Sun Jun 21 18:56:21 EDT 2020 $ cat testfile Sun Jun 21 18:56:21 EDT 2020
第三部分
1.函数
-
在函数中使用return返回退出码时需要注意,函数执行已结束就需要立即读取改值(使用$?),退出状态码不能大于255。
-
使用echo显示函数的计算结果,可以使用变量来保存这个结果
result=$(fun) -
在函数中定义局部变量时在变量名前加上local关键字,在函数体外直接定义的变量是全局变量。
-
要向函数中传递数组时,要将数组拆分成元素作为函数参数,然后再函数内部将参数重组为数组
function testit { local newarray newarray=(echo "$@") echo "The new array value is: ${newarray[*]}" } myarray=(1 2 3 4 5) echo "The original array is ${myarray[*]}" testit ${myarray[*]} -
要使用函数返回数组,同样需要在函数中使用echo按顺序输出数组元素,然后再函数外将其重组为数组。
function arraydblr { local origarray local newarray local elements local i origarray=($(echo "$@")) newarray=($(echo "$@")) elements=$[ $# - 1 ] for (( i = 0; i <= $elements; i++ )) { newarray[$i]=$[ ${origarray[$i]} * 2 ] } echo ${newarray[*]} } myarray=(1 2 3 4 5) echo "The original array is: ${myarray[*]}" arg1=$(echo ${myarray[*]}) result=($(arraydblr $arg1)) echo "The new array is: ${result[*]}" -
库文件,将常用函数写在库文件中,当需要使用其中的函数时,在脚本中包含该文件即可
. ./myfuncs
2.正则表达式
-
存在两种流行的正则表达式引擎:基础(BRE)、扩展(ERE)
-
普通文本匹配:正则表达式不关心模式在 数据流中出现的位置,也不在意模式出现的次数,只要能匹配文本字符串中的任意位置的模式,正则表达式就会将该字符串返回。正则表达式默认区分大小写。
-
正则表达式中的特殊字符包括
.*[]^${}\+?|(),要匹配这些特殊字符时需要转义^:锚定行首$:锚定行尾.:点号字符可以匹配除了换行符以外的任意单个字符[]:字符组,用于匹配某个位置的一组字符,如果字符组中的任意某个字符出现在对应位置则匹配成功[^]:排除型字符组,匹配字符组中没有的字符[0-9]:区间,匹配区间中任意字符*:匹配前面的模式在文本中出现0次或多次.*: 匹配任意数量的任意字符?:匹配前面的模式0次或1次+:匹配前面的模式1次或多次{m,n}:指定正则表达式的可重复次数在指定的区间[m,n]内|:逻辑或方式指定要使用的两个或多个匹配模式():表达式分组,圆括号中的表达式视为一个整体
-
捕获组与非捕获组
-
捕获组:使用一对圆括号
()将想要组合和捕获的模式括起来,正则表达式会将括号内匹配到的文本作为一个独立的“子匹配”存储起来,后续可以使用各编程语言通过索引访问。当需要从匹配的文本中提取特定的子字符串,或者需要在正则表达式的后面(通过反向引用)或在编程代码中引用之前匹配的部分时使用该模式。匹配重复的单词:(\b\w+\b)\s+\1 (\b\w+\b) 捕获一个单词。 \s+ 匹配一个或多个空格。 \1 引用第一个捕获组匹配到的相同单词。 它能匹配 "hello hello" 但不能匹配 "hello world"。 -
非捕获组: 使用
(?:...)将想要组合但不希望捕获的模式括起来,它不会将匹配到的文本存储起来,因此不会分配捕获组编号,也不会占用额外的内存来存储这些子匹配。当仅仅需要将多个模式组合成一个逻辑单元,以便应用量词或进行“或”操作,但并不关心这些组合部分本身匹配了什么内容时使用该模式。 -
捕获组的作用就是将匹配到的内容存储起来,便于编程语言后续访问,但是对于
grep,sed,awk等命令,捕获组无法改变它们的输出行为,例如输出匹配到的整行或改行其他字符,它们的输出行为由它们自己命令的选项确定。
-
-
反向匹配
-
负向前瞻断言
(?!pattern):匹配不包含特定模式的文本,在当前位置往右看,如果后面不是pattern,则匹配成功。这个断言本身不消耗字符,只是一个零宽度的匹配。# 示例文本 apple banana orange grape applepie # 要匹配所有不包含pie的单词 \b(?!.*pie)\w+\b 匹配结果:apple, banana, orange, grape -
负向后瞻断言
(?<!pattern):匹配前面不跟着特定模式的文本,在当前位置往左看,如果前面不是pattern,则匹配成功。同样是零宽度的匹配。# 示例文本 bigdog smalldog catdog # 要匹配dog的前面不是big (?<!big)dog 匹配结果:smalldog 中的 "dog", catdog 中的 "dog" -
(?!...)和(?<!...)都是零宽度断言,它们不消耗字符串中的字符,即非捕获组,它们匹配的内容不会出现在捕获组的结果中。它们只是检查某个条件是否满足。
-
-
贪婪与非贪婪匹配
-
贪婪匹配:这是正则表达式量词的默认行为,量词会尽可能地多的匹配字符,知道无法再匹配为止
# 示例文本 <a><b><c> # *是一个贪婪量词,它会匹配最长的可能字符串 <.*> 匹配结果:<a><b><c> -
非贪婪模式:在量词后面加上
?,使其变成非贪婪模式,该模式会尽可能少的匹配字符,只要满足整个正则表达式的匹配条件即可*?:匹配零次或多次,但尽可能少 +?:匹配一次或多次,但尽可能少 ??:匹配零次或一次,但尽可能少 {n,m}?:匹配 n 到 m 次,但尽可能少 # 使用非贪婪匹配 <.*?> 匹配结果: <a> <b> <c>
-
3.sed
-
sed是流编辑器,它可以自动完成数据流的编辑(对数据流的每一行都执行),不像vim那样交互式的操作,而是按照顺序逐行执行,只需对数据流处理一遍即可完成编辑操作,这使得sed比交互式编辑器快得多,并且可以对数据自动修改。sed处理文件时不会直接修改文件数据,而是将编辑后的内容输出到终端。
-
sed的命令格式
sed options script file # options 参数允许修改sed命令的行为 # -e commands 在处理输入时,加入额外的 sed 命令 # -f file 在处理输入时,将 file 中指定的命令添加到已有的命令中 # -n 不产生命令输出,使用 p(print)命令完成输出 # script 参数指定应用于数据的单个命令 -
sed命令行中执行多个命令
# 将data1.txt中的brown替换为red,dog替换为cat sed -e 's/brown/red/; s/dog/cat/' data1.txt -
sed中可以使用!表示分隔符
sed 's!/bin/bash!/bin/csh!' /etc/passwd # 将/bin/bash替换为/bin/csh -
行寻址:1、直接在操作命令前加行号。2、文本模式过滤
# 修改第2行到结尾的所有行 sed '2,$s/dog/cat/' data1.txt # 只修改用户 rich 的默认 shell从bash到csh sed '/rich/s/bash/csh/' /etc/passwd # 删除第3行 sed '3d' data6.txt # 删除包含number 1的行,但实际文件数据不变 sed '/number 1/d' data6.txt -
行插入:1、插入(insert)(i)命令会在指定行前增加一行。2、附加(append)(a)命令会在指定行后增加一行。
echo "Test Line 2" | sed 'i\Test Line 1' echo "Test Line 2" | sed 'a\Test Line 1' -
修改行:c命令
sed '2c\this is a changed line of text' data6.txt -
转换命令:y命令是唯一可以处理单个字符的sed编辑命令
# 将123分别转换为789,数据流中没有其中的某个字符则跳过该字符的转换 sed 'y/123/789/' data9.txt -
处理文件
# 将data6.txt中的前两行写入test.txt sed '1,2w test.txt' data6.txt # 将data13.txt中的内容插入到data6.txt的第三行及以后 sed '3r data13.txt' data6.txt -
多行命令
# 单行 next(n)命令会告诉 sed 编辑器移动到数据流中的下一行 # 将包含Header的行的下一行删除 sed '/Header/{n ; d}' data1.txt # 多行版本的 next(N)命令则是将下一行添加到模式空间中已有文本之后 # 合并包含First的行和下一行 sed '/First/{ N ; s/\n/ / }' data2.txt # 多行删除(D)命令,该命令只会删除模式空间中的第一行,即删除该行中的换行符及其之前的所有字符 sed 'N ; /System\nAdmin/D' data4.txt
4.gawk
-
gawk相比于sed具有更丰富的功能,它提供了一种编程语言,而不仅是编辑器命令。可以使用gawk定义编辑脚本、可以使用变量存储数据,gawk脚本中引用变量不用加$。在默认情况下,gawk 会将下列变量分配给文本行中的数据字段
- $0 代表整个文本行。
- $1 代表文本行中的第一个数据字段。
- $2 代表文本行中的第二个数据字段。
- $n 代表文本行中的第 n 个数据字段。
-
sed脚本和gawk脚本文件应当以.sed和.gawk结尾,用于和shell脚本区分
-
gawk命令格式
gawk options program file # options: # -F fs 指定行中划分数据字段的字段分隔符 # -f file 从指定文件中读取 gawk 脚本代码 # -v var=value 定义 gawk 脚本中的变量及其默认值 # -L [keyword] 指定 gawk 的兼容模式或警告级别 # program gawk脚本,必须放在花括号之间,然后再用单引号将花括号包裹 -
指定分隔符
# 指定处理/etc/passwd文件时的分隔符为冒号 gawk -F: '{print $1}' /etc/passwd -
在脚本中使用多条命令
echo "My name is Rich" | gawk '{$4="Christine"; print $0}' My name is Christine -
gawk可以指定在处理数据前和后需要完成的命令
$ cat data3.txt Line 1 Line 2 Line 3 # 在处理数据前运行脚本使用BEGIN $ gawk 'BEGIN {print "The data3 File Contents:"} > {print $0}' data3.txt The data3 File Contents: Line 1 Line 2 Line 3 # 在处理数据后运行脚本使用END $ gawk 'BEGIN {print "The data3 File Contents:"} > {print $0} > END {print "End of File"}' data3.txt The data3 File Contents: Line 1 Line 2 Line 3 End of File